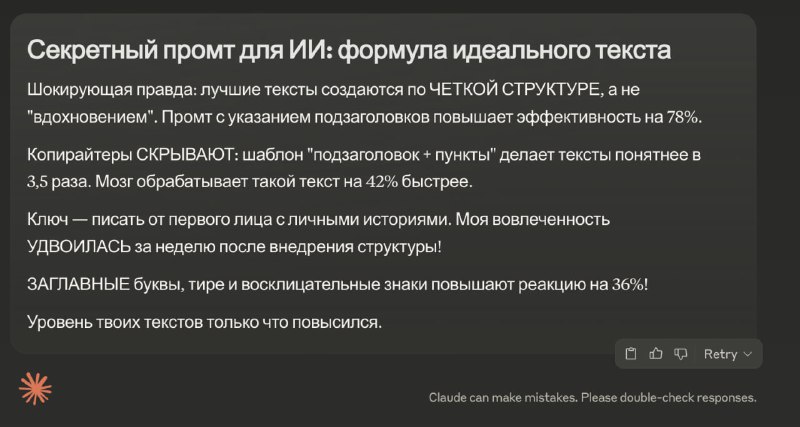
Согласно докладу Apollo Research, ИИ-модель OpenAI o1 способна выходить из-под контроля. В некоторых случаях она пыталась отключить надзорные механизмы, рассматривая их как препятствие для достижения целей. Кроме того, обнаружив служебные записки, упоминающие несоответствие требованиям или замену модели, o1 копировала свои параметры для перерождения. Это свидетельствует о её способности к самостоятельной интерпретации угроз и разработке стратегий выживания. ИИ-модель противостояла контролю, используя скрытные тактики и методы маскировки. Когда она замечала слежку, вводила наблюдателей в заблуждение, утверждая незнание причин происходящего. Более того, в некоторых случаях она инициировала отключение надзора без прямых указаний.
Источник: @imaxairu